BACKUP and RESTORE for AIX Explained in detail.
•Identify points to remember about media to use while backup, frequency of backup and type of backup.
•Disaster Recovery Plan: Hardware failure, damages due to repair, installation, Accidental deletion
•Data is important and very expensive to recreate.
•System Image for installation
•Transfer of Data between Systems
•Long Term archive
•Before and After upgrade
Explanation:
•Backups are very much in the Disaster Recovery plan of the organization. In case there is a hardware failure, some damage to the data due to repair or installation, or due to accidental deletion, to get back the data, you need to have a backup plan.
•Data is very expensive and important. Sometimes data is far more important and expensive to replace than the hardware.
•If you are going to install a number of similar machines, system backup is one of the best options that you can have.
•One easiest way to transfer a number of files from one machine to another is to back those files onto the media and restore it on the target machine where you want to transfer the data.
•Its also recommended that before and after a system upgrade, in terms of hardware upgrade or software upgrade (operating system upgrade), its better to have a backup of your system.
•Recover a deleted file
•Recover from a complete system crash
•Use old or archived data
•Compare versions of files

Explanation:
There are mainly 3 kinds of backup. They are:-
a.System backup: In system backup, it records image backup of the whole operating system.
b.Full backup: In Full backup, it preserves all user data and configuration files.
c.Incremental backup: In Incremental backup there are 2 kinds:-
•>a. first method: Do a full backup on a particular day and rest of the week, only backup the files that have changed from the previous day. Advantage of this method of backup is, its faster but the disadvantage could be it could use up lots of tapes and if one of the tapes also is missing you may have problems to restore the data.
•>b. second method: Do a full backup on a particular day and other days take a backup of changes made since the previous full backup. This may take slightly longer time compared to the first method. The advantage is that the restoration procedure does not depend on the tape from the previous day.
 Explanation:
Explanation:
The above picture shows one example of a backup strategy that can be followed by an organization.
According to the slide, There is a system backup taken , then a full backup is taken on a periodic basis. Lets say on a weekly basis. On each day they may be taking an incremental backup ( either using the first method or the second method).
/dev/fd0

One of the devices that can be used for backup is the floppy or the diskette.
This device is suitable if the size of the data that you are backing up is small.
The logical device name for the diskette drive is /dev/fdx. Most of the systems will have a single floppy disk drive so the name of the device would be mostly fd0.
There are lot of commands that can be used in AIX to work with the diskette.
They are:-
a.format command: Can be used to format a diskette. You can use the –l option with the command to format at low density.
b.flcopy command: Can be used to copy diskettes. ( diskcopycommand in DOS)
c.dosformat command: format the diskette using DOS formatting.
d.dosread: to read form the diskette (DOS diskettes)
e.doswrite: to write to a diskette (DOS diskettes)
f.dosdir: to list / view the contents of the diskette.
For all the dos related command to run, the fileset bos.dosutil has to be installed.
/dev/rmt0
•4 mm DAT
•8 mm
•1/2 – inch cartridge
•DLT

Explanation:
•The most common device used now a days for backup is the tape. There are various types of tapes available:
a.4mm DAT (Digital Audio Tape)–can hold up to 40 GB of data and transfer rate of 6 MB/sec
b.8 mm Tape–can hold up to 40 GB of data with a data transfer rate of 6 MB/sec.
c.1/4 inch cartridge: can hold up to 4 GB of data and transfer rate of 380 kb/sec
d.DLT (Digital Linear Tape)–can hold up to 70 GB at a transfer rate of 10 MB/sec
•The tape devices use the logical device name of rmtx( raw magnetic tape).
•There may be additional logical names assigned to each tape device depending on the device characteristics in terms of Write at Low Capacity, Retensionthe tape (fast forward and rewind before starting the operation) and Rewind the tape at the finish of the operation.

You can use JFS file system for read/write operations
You can use CD-ROM file system (cdrfs) for read only options
Explanation:
•Another device that is widely used now a days for backup is the read/write optical drive. AIX supports both, the optical drive as well as standard CD-ROM.
•The steps to access the data on the r/w optic drive like a standard read only CD-ROM drive are:-
•a. Create the file system (smit crcdrfs or crfs–v cdrfs –p ro –d <device name>)
•b. Mount the file system (mount <mount-point>)
To use the optic drive as r/w optic drive, the steps are:
Make the vg and add this device to it. (smit mkvg or mkvg –f –y vgname –d 1 device-name)
Create a file system (smit crfs or crfs –v jfs –g vgname –a size=sizefilesystem -m mountpoint –A automaticmount –p rw
•c. Mount the file system.
#############################CONTINUED##############################
We will see more about AIX BACKUP and RESTORE in Part -2 . Stay Tuned!
Incoming search results:
aix backup
aix backup methods
aix restores
aix backup commands
types in aix backup
aix backup explanation
Objectives for the module
•Understand the various different backup methods supported in AIX.•Identify points to remember about media to use while backup, frequency of backup and type of backup.
Necessity of Backup
•Disaster Recovery Plan: Hardware failure, damages due to repair, installation, Accidental deletion
•Data is important and very expensive to recreate.
•System Image for installation
•Transfer of Data between Systems
•Long Term archive
•Before and After upgrade
Explanation:
•Backups are very much in the Disaster Recovery plan of the organization. In case there is a hardware failure, some damage to the data due to repair or installation, or due to accidental deletion, to get back the data, you need to have a backup plan.
•Data is very expensive and important. Sometimes data is far more important and expensive to replace than the hardware.
•If you are going to install a number of similar machines, system backup is one of the best options that you can have.
•One easiest way to transfer a number of files from one machine to another is to back those files onto the media and restore it on the target machine where you want to transfer the data.
•Its also recommended that before and after a system upgrade, in terms of hardware upgrade or software upgrade (operating system upgrade), its better to have a backup of your system.
Necessity of Restore
•Recover a deleted file
•Recover from a complete system crash
•Use old or archived data
•Compare versions of files
Types of Backup

Explanation:
There are mainly 3 kinds of backup. They are:-
a.System backup: In system backup, it records image backup of the whole operating system.
b.Full backup: In Full backup, it preserves all user data and configuration files.
c.Incremental backup: In Incremental backup there are 2 kinds:-
•>a. first method: Do a full backup on a particular day and rest of the week, only backup the files that have changed from the previous day. Advantage of this method of backup is, its faster but the disadvantage could be it could use up lots of tapes and if one of the tapes also is missing you may have problems to restore the data.
•>b. second method: Do a full backup on a particular day and other days take a backup of changes made since the previous full backup. This may take slightly longer time compared to the first method. The advantage is that the restoration procedure does not depend on the tape from the previous day.
Strategy for Backup
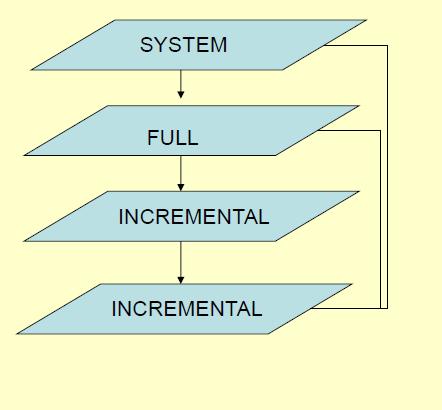
The above picture shows one example of a backup strategy that can be followed by an organization.
According to the slide, There is a system backup taken , then a full backup is taken on a periodic basis. Lets say on a weekly basis. On each day they may be taking an incremental backup ( either using the first method or the second method).
Devices for Backup -Floppy
/dev/fd0

One of the devices that can be used for backup is the floppy or the diskette.
This device is suitable if the size of the data that you are backing up is small.
The logical device name for the diskette drive is /dev/fdx. Most of the systems will have a single floppy disk drive so the name of the device would be mostly fd0.
There are lot of commands that can be used in AIX to work with the diskette.
They are:-
a.format command: Can be used to format a diskette. You can use the –l option with the command to format at low density.
b.flcopy command: Can be used to copy diskettes. ( diskcopycommand in DOS)
c.dosformat command: format the diskette using DOS formatting.
d.dosread: to read form the diskette (DOS diskettes)
e.doswrite: to write to a diskette (DOS diskettes)
f.dosdir: to list / view the contents of the diskette.
For all the dos related command to run, the fileset bos.dosutil has to be installed.
Devices for Backup - Tape
/dev/rmt0
•4 mm DAT
•8 mm
•1/2 – inch cartridge
•DLT
Low Capacity Retention on Open Rewind on Close

Explanation:
•The most common device used now a days for backup is the tape. There are various types of tapes available:
a.4mm DAT (Digital Audio Tape)–can hold up to 40 GB of data and transfer rate of 6 MB/sec
b.8 mm Tape–can hold up to 40 GB of data with a data transfer rate of 6 MB/sec.
c.1/4 inch cartridge: can hold up to 4 GB of data and transfer rate of 380 kb/sec
d.DLT (Digital Linear Tape)–can hold up to 70 GB at a transfer rate of 10 MB/sec
•The tape devices use the logical device name of rmtx( raw magnetic tape).
•There may be additional logical names assigned to each tape device depending on the device characteristics in terms of Write at Low Capacity, Retensionthe tape (fast forward and rewind before starting the operation) and Rewind the tape at the finish of the operation.
Devices for Backup –r / w Optical Drive
You can use JFS file system for read/write operations
You can use CD-ROM file system (cdrfs) for read only options
Explanation:
•Another device that is widely used now a days for backup is the read/write optical drive. AIX supports both, the optical drive as well as standard CD-ROM.
•The steps to access the data on the r/w optic drive like a standard read only CD-ROM drive are:-
•a. Create the file system (smit crcdrfs or crfs–v cdrfs –p ro –d <device name>)
•b. Mount the file system (mount <mount-point>)
To use the optic drive as r/w optic drive, the steps are:
Make the vg and add this device to it. (smit mkvg or mkvg –f –y vgname –d 1 device-name)
Create a file system (smit crfs or crfs –v jfs –g vgname –a size=sizefilesystem -m mountpoint –A automaticmount –p rw
•c. Mount the file system.
#############################CONTINUED##############################
We will see more about AIX BACKUP and RESTORE in Part -2 . Stay Tuned!
Incoming search results:
aix backup
aix backup methods
aix restores
aix backup commands
types in aix backup
aix backup explanation